Was ist „Big Data“?

Foto: RAEng_Publications, Pixabay
Eine eindeutige und feststehende Definition des Begriffs „Big Data“ gibt es nicht, wohl aber teilen sich viele Begriffsklärungen eine oder mehrere Aussagen in Bezug auf die Menge, die Strukturiertheit und die angewendeten Technologien zur Auswertung digitaler Daten.1
Big Data setzt leistungsfähige Speichermedien voraus, um kontinuierlich digitale Daten zu sammeln und mithilfe von Algorithmen und Maschinen Lernen auszuwerten. Big Data und dadurch möglichen Analysen (Big Data Analytics) sind eine Folge der digitalen Transformation unserer Gesellschaft, der exponentiell gestiegenen Kapazität von Speichertechnologien und der ebenfalls gestiegenen Leistungsfähigkeit von Prozessoren und Algorithmen.
- Big Data aus einer medienwissenschaftlichen Sicht – Sammelbegriff für technische Verfahren zur Erfassung, Speicherung und Analyse vielfältiger und sehr großer digitaler Datenmengen. Verweist außerdem auf utopische sowie dystopische Rhetoriken zur Auswertung großer Datensätze.
Weitere Informationen zu Big Data aus einer informatischen Sicht:
- Big Data (Lexikoneintrag)
Häufig in der Literatur zitiert wird die Charakterisierung von Big Data über englischsprachige „V“-Begriffe.2, 3
Demnach zeichnet sich Big Data aus durch: „Volume“, „Velocity“ und „Variety“.
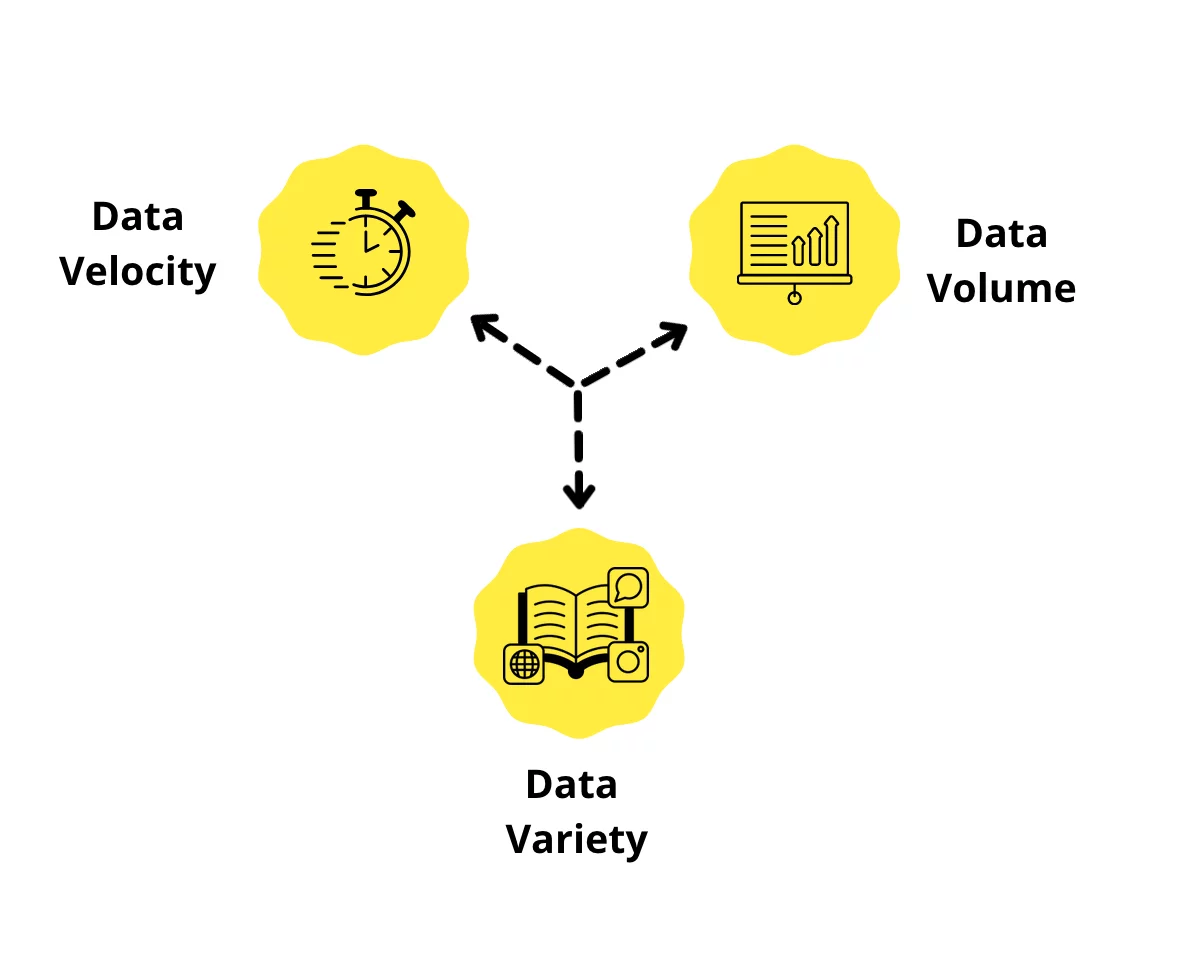
Data Volumen
Data Volume
Die Menge an Daten, zu deren Bearbeitung konventionelle Datenbanksysteme nicht mehr ausreichen und verteilte, parallele Systeme eingesetzt werden.
Data Variety
Data Variety
Die unstrukturierte Beschaffenheit der Daten jedweden Formats (Text‑, Bild‑, Audio- und Videodaten, Metadaten usw.) im Unterschied zu den strukturierten, traditionellen Datenbanksystemen.
Data Velocity
Data Velocity
Die Geschwindigkeit bzw. Beschleunigung des Datenverkehrs und die Analyse der Daten in Echtzeit.
Grafische Aufarbeitung des V-Modell für Big Data nach Klein, Tran-Gia & Hartmann (2013)4: I Team Digitale Lehre des ZfL der Universität zu Köln (https://zfl.uni-koeln.de/) I CC BY-SA 4.0 (https://creativecommons.org/licenses/by- sa/4.0/)
Big Data – Erklärfilm – Das knapp drei Minuten lange Erklärvideo von explain-it zu Big Data aus dem Jahr 2014 erläutert den Begriff, die Entstehung von Daten sowie Anwendungsbeispiele.

Foto: Markus Spiske von Unsplash
Unterrichtseinheit „Was ist Big Data?“ – Diese Einheit nimmt 45 Minuten in Anspruch und richtet sich an Schülerinnen und Schüler im Alter von 12 bis 16 Jahren an Gymnasien, Real- und Hauptschulen. Es wird der Begriff „Big Data“ eingeführt und erklärt, wie und welche Mengen an Daten im Alltag produziert werden. Die Materialien stehen zum Download zur Verfügung. Die „Digitale Lernwerkstatt“ ist ein Projekt der Accenture Dienstleistungen GmbH.

Foto: Stephen Dawson auf Unsplash
In seiner im November 2017 veröffentlichten Stellungnahme zu Big Data im Gesundheitswesen legt der Deutsche Ethikrat folgende Arbeitsdefinition zugrunde:
5
Im Folgenden stehen nicht die informatisch-technischen Bearbeitungen von Big Data im Vordergrund, sondern die gesellschaftlich-kulturellen Auswirkungen und sozialen Folgen, die sich durch die Auswertung von Big Data ergeben. Big Data bezeichnet nicht nur das bloße Vorhandensein gigantischer und heterogener Datenbestände, sondern schließt auch ihre Auswertung mit Hilfe von Künstlicher Intelligenz und Maschinelles Lernen ein.
Die visuelle Einführung ins Maschinelle Lernen von R2D3 zeigt, wie Computer statistische Lernverfahren anwenden, um automatisch Muster in Daten zu erkennen. Dies ermöglicht sehr genaue Vorhersagen zu treffen. Beispielhaft werden diese Verfahren anhand von Daten aus dem Immobilienmarkt dynamisch veranschaulicht.

Foto: Markus Winkler von Unsplash
3. Muster und Vorhersagen im Datenüberschuss
Big Data (Analytics) erweitert die Möglichkeiten zur Erzeugung und Auswertung von Daten über die Welt. Für Viktor Mayer-Schönberger ist Big Data „weniger eine neue Technologie denn eine neue oder jedenfalls signifikant verbesserte Methode der Erkenntnisgewinnung“.6 Es geht bei Big Data „nicht um die absolute Zahl an Daten“, sondern um die Vorgehensweise relativ zum Phänomen bzw. zur Frage, die beantwortet werden soll, „deutlich mehr Daten“ zu sammeln und auszuwerten.7
Dieser Datenüberschuss bietet Möglichkeiten, bislang unerkannte Muster und statistische Korrelationen als Antworten auf Fragen zukünftigen Handelns zu erzeugen. Je nach Fragestellung wurden verschiedene Anwendungen entwickelt, die auch „prädiktive Analytik“ bezeichnet werden:
- Welche Mitarbeiterin steht kurz davor, selbst zu kündigen? – People Analytics
- Wo könnte die nächste Straftat passieren? – Predictive Policing
- Welches Produkt wird die Kundin als nächstes kaufen? – Predictive Marketing
- Welches Bauteil wird in den kommenden Tagen kaputtgehen und muss jetzt ausgetauscht werden? – Predictive Maintainance
- Welches Kind ist durch Gewalt in der Familie akut gefährdet? – Risk Scoring
- Welche Studentin wird die Prüfung nicht bestehen? – Learning Analytics
Zur Beantwortung derartiger Fragestellungen werden Big Data Technologien eingesetzt, um vermeintlich „neutrale“ Antworten auf Basis „objektiver Daten“ zu liefern. Die Zuschreibungen von Neutralität, Objektivität und somit Rationalität mit Blick auf die sozialen Folgen wurden indes wiederholt in Frage gestellt.
 Was ist „prädiktive Analytik“?
Was ist „prädiktive Analytik“?
Was ist „prädiktive Analytik“?„In der ‚prädiktiven Analytik‘ möchte man also anhand leicht zugänglicher Daten schwer zugängliche Daten über Individuen abschätzen. Prädiktive Analytik entsteht überall dort, wo durch alltäglich verwendete digitale Medien massenweise Verhaltens- und Nutzungsdaten anfallen. Das liegt daran, dass prädiktive Modelle den einzelnen Fall anhand von ‚pattern matching‘ [dt. Musterabgleich oder musterbasierte Suche] mit Millionen anderer Fälle abgleichen, ihn einer algorithmisch bestimmten Gruppe besonders ähnlicher Fälle zuordnen und daraus eine Schätzung der unbekannten Zielvariable ableiten.
In den meisten Fällen werden solche Modelle mit Verfahren des überwachten Lernens trainiert: Dazu wird eine große Menge sog. ‚Trainingsdaten‘ benötigt, ein Datensatz, in dem für eine Kohorte von Individuen beide Datenfelder, also sowohl die Hilfsdaten als auch die sensiblen Zieldaten, erfasst sind. Solche Datensätze fallen regelmäßig im Kontext sozialer Alltagsmedien an, zum Beispiel produziert die Teilmenge aller Facebook-Nutzer*innen, die in ihrem Profil explizit Angaben über ihre sexuelle Orientierung machen, einen Trainingsdatensatz zur Abschätzung der sexuellen Identität; und die Gruppe der Individuen, von denen man gleichzeitig Zugriff auf ihren Browserverlauf und die Daten einer Gesundheits-App hat, produzieren Trainingsdaten für eine KI, die anhand von Browserverläufen Krankheitsdispositionen abzuschätzen lernen kann.
Sobald eine Gruppe von einigen Tausend Individuen freiwillig oder unwissentlich zugleich Hilfsdaten und sensible Daten preisgibt, kann ein Machine-Learning-Modell trainiert werden, welches Korrelationen zwischen den Hilfsdaten und den sensiblen Daten ermittelt. Solche Modelle werden anschließend dazu verwendet, die sensible Zielvariable auch für Individuen abzuschätzen, über die nur die Hilfsdaten bekannt sind und die selbst keine sensiblen Daten über sich preisgeben würden.“8
 Quellen
Quellen
Quellen1 Vgl. Ward, J. S. & Barker, A. (2013, 20 September). Undefined By Data: A Survey of Big Data Definitions. Abgerufen am 17. Mai 2022, von https://arxiv.org/abs/1309.5821.
2 Vgl. Laney, D. (2001, 6. Februar). 3D Data Management: Controlling Data Volume, Velocity, and Variety. Abgerufen am 17. Mai 2022, von https://idoc.pub/documents/3d-data-management-controlling-data-volume-velocity-and-variety-546g5mg3ywn8.
3 Vgl. Isitor, E. & Stanier, C. (2016). Defining Big Data. In D. E. Boubiche, H. Hamdan & A. Bounceur (Hrsg.), BDAW 2016. Proceedings of the International Conference on Big Data and Advanced Wireless Technologies. New York: ACM, 5. https://doi.org/10.1145/3010089.3010090.
4 Vgl. Klein, D., Tran-Gia, P. & Hartmann M. (2013, 1. Juli). Big Data. Abgerufen am 17. Mai 2022, von https://gi.de/informatiklexikon/big-data/.
5 Deutscher Ethikrat (2017, 30. November). Big Data und Gesundheit – Datensouveränität als informationelle Freiheitsgestaltung [Stellungnahme], hier: S. 36, i.O. kursiv.
https://www.ethikrat.org/fileadmin/Publikationen/Stellungnahmen/deutsch/stellungnahme-big-data-und-gesundheit.pdf.
6 Mayer-Schönberger, V. (2015). Was ist Big Data? Zur Beschleunigung des menschlichen Erkenntnisprozesses. Aus Politik und Zeitgeschichte, 65(11–12), 14–19, hier S. 15.
7 Ebd.
8 Mühlhoff, R. (2020). Prädiktive Privatheit. Warum wir alle „etwas zu verbergen haben“. In Interdisziplinäre Arbeitsgruppe Verantwortung: Maschinelles Lernen und Künstliche Intelligenz der Berlin-Brandenburgischen Akademie der Wissenschaften (Hrsg.), KI als Laboratorium? Ethik als Aufgabe (S. 37-44). Berlin-Brandenburgische Akademie der Wissenschaften, hier S. 44. https://www.bbaw.de/files-bbaw/user_upload/publikationen/BBAW_Verantwortung-KI‑3–2020_PDF-A-1b.pdf.